 域名频道IDC知识库
域名频道IDC知识库DeepSeek是一款高性能的AI模型,其性能可与OpenAI的o1模型媲美,适用于多种复杂应用场景。通过本地部署,用户不仅能充分发挥DeepSeek的强大功能,还能显著提升数据的隐私性和安全性,非常适合对数据控制有高要求的企业或个人。
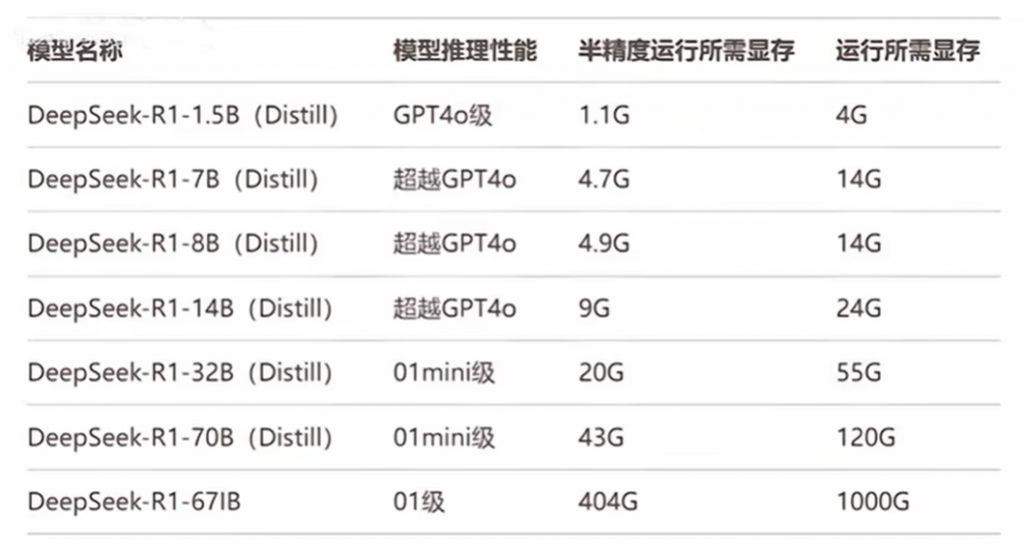
DeepSeek作为一款强大的AI模型,其本地部署对硬件有一定的要求。DeepSeek 本地化部署的电脑配置要求需根据模型规模(如 7B、13B、70B 参数)和量化方案(如 FP16、INT8、4-bit 量化)进行区分,以下是具体配置建议:
一、最低配置(勉强运行基础模型)
-
适用场景:运行量化版小模型(如 4-bit 量化 7B 参数)。
-
性能预期:CPU 推理延迟较高(10-30 秒/回答),勉强完成基础文本生成。
-
硬件配置:
- CPU:支持 AVX2 指令集的四核处理器(Intel i5 8 代+/AMD Ryzen 3000+)。
- 内存:16GB DDR4(需满足量化模型加载,7B-4bit 约需 4GB 内存)。
- 显卡:可选低端独显(如 NVIDIA GTX 1650 4GB)加速部分计算。
- 存储:50GB SSD(模型文件+系统环境)。
- 量化方案:必须使用 4-bit/8-bit 量化模型。
- 示例模型:DeepSeek-7B-4bit、DeepSeek-Mini。
二、推荐配置(流畅运行中等模型)
-
适用场景:FP16 精度下运行 13B 参数模型,或 8-bit 量化 70B 模型。
-
性能预期:GPU 加速响应(3-10 秒/回答),支持多轮对话。
-
硬件配置:
- CPU:六核处理器(Intel i7 10 代+/AMD Ryzen 5 5000+)。
- 内存:32GB DDR4(13B-FP16 需约 26GB 内存)。
- 显卡:NVIDIA RTX 3090 24GB/RTX 4090 24GB(单卡加载 13B-FP16)。
- 存储:200GB NVMe SSD(高速加载大模型文件)。
- 优化建议:启用 CUDA 加速+vLLM 推理框架。
- 示例模型:DeepSeek-13B、DeepSeek-70B-8bit。
三、最佳配置(高性能多卡部署)
-
适用场景:无损精度运行百亿级大模型(如 70B/130B),支持长文本生成与低延迟。
-
性能预期:亚秒级响应(0.5-2 秒/回答),百人级并发请求。
-
硬件配置:
- CPU:线程撕裂者/至强 W 系列(24 核+,保障数据传输带宽)。
- 内存:128GB DDR5 ECC(全精度 70B 模型需约 140GB 内存)。
- 显卡:双卡 NVIDIA A100 80GB/H100 80GB(通过 TensorRT-LLM 优化)。
- 存储:1TB PCIe 4.0 SSD 阵列(模型秒级加载)。
- 网络:可选 RDMA 高速互联(多卡 NVLink/NVSwitch)。
- 示例模型:DeepSeek-70B-FP16、DeepSeek-XL。
四、其他配置建议
- 模型量化:4-bit 量化可使显存需求降低至 1/4,但可能损失部分生成质量。
- 推理框架:vLLM/PyTorch-LLM 可提升吞吐量,TGI 支持动态批处理。
- 显存估算:FP16 模型显存 ≈ 参数量×2 字节(例:13B×2=26GB)。
- 云部署替代:70B+模型建议使用云端 A100/H100 集群(如 AWS p4d 实例)。
综上所述,DeepSeek的本地部署需要高性能的硬件支持和完善的软件环境。通过选择合适的CPU、内存、存储和网络配置,并配备兼容的操作系统、Python环境及数据库,用户可以高效地运行DeepSeek模型。本地部署不仅能充分发挥其强大性能,还能保障数据隐私和安全。建议用户根据实际需求和模型规模灵活调整配置,以获得最佳的部署效果。DeepSeek本地部署的硬件需求涉及多个方面,合理配置这些硬件组件是确保模型顺利运行并发挥出最佳性能的关键。
域名频道为客户提供服务器代维服务,为客户节约服务器维护成本,费用不到专职人员的十分之一。
服务器托管与单独构建机房和租用专线上网相比、其整体运营成本有较大降低。
网站空间可随意增减空间大小,空间升级可以按照对应的产品号升级到相对应的空间类型。随时随地能达到用户的使用要求。
您有自己的独立服务器,需要托管到国内机房,我们为你提供了上海电信五星级骨干机房,具体请查看http://www.dns110.com/server/ai-server.asp