 域名频道IDC知识库
域名频道IDC知识库DeepSeek R-1被视为一种完全开放的模型,这意味着任何人都可以采用基本的代码库,对其进行调整,甚至根据自己的需求进行微调。从技术的角度来看,DeepSeek R-1(通常以R1的缩写为R1)源于一种称为DeepSeek-V3的大型基本模型。然后,实验室通过在高质量的人类标记的数据和增强学习(RL)上结合了监督的微调(SFT)来完善该模型。
如何在本地运行DeepSeek?
要在本地运行DeepSeek R-1,我们将使用一种称为Ollama的工具。Ollama是一种免费的开源工具,允许用户在其计算机上本地运行大型语言模型(LLMS)。它可用于MacOS,Linux和Windows。前往Ollama官方网站,然后单击“下载”按钮。将其安装在系统上。
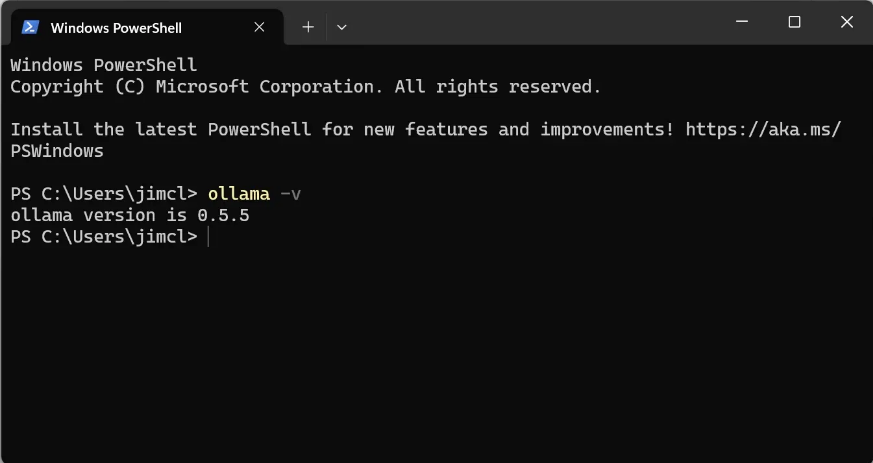
安装完成后,在终端或命令提示符中运行以下命令以检查Ollama是否安装成功:
ollama -v
在“模型”选项卡下,搜索关键字“ DeepSeek”,您应该在搜索列表上的第一个项目上看到“ DeepSeek-r1”。
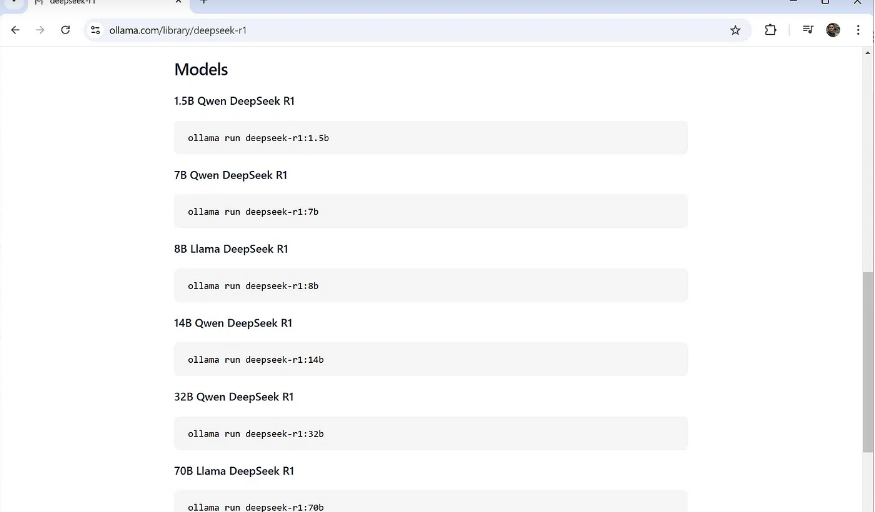
单击它,然后在模型部分下进行,您会注意到有多个型号尺寸从50亿到6710亿个参数。根据经验,较大的型号需要更强大的GPU才能运行。
诸如80亿参数版本之类的较小型号可以使用8GB的VRAM在GPU上运行。较大的模型需要更多的资源(请参阅下面的VRAM和GPU要求部分)。要下载并运行80亿个参数模型,请使用以下命令:
ollama run deepseek-r1:8b
该模型将开始下载(约4.9GB)。在继续前,请确保您有足够的磁盘空间。
下载后,该型号将在您的计算机上本地运行。您可以立即与之聊天。
其他ollama可以做的事情:
- 在本地运行LLMS,包括Llama2,Phi 4,Mistral和Gemma 2
- 允许用户创建和共享自己的LLM
- 捆绑型号的权重,配置和数据到一个软件包中
- 优化设置和配置详细信息,包括GPU使用
GPU和VRAM要求
DeepSeek-R1的VRAM要求取决于模型大小,参数计数和量化技术等因素。以下是DeepSeek-R1及其蒸馏模型的VRAM需求的详细概述,以及推荐的GPU:
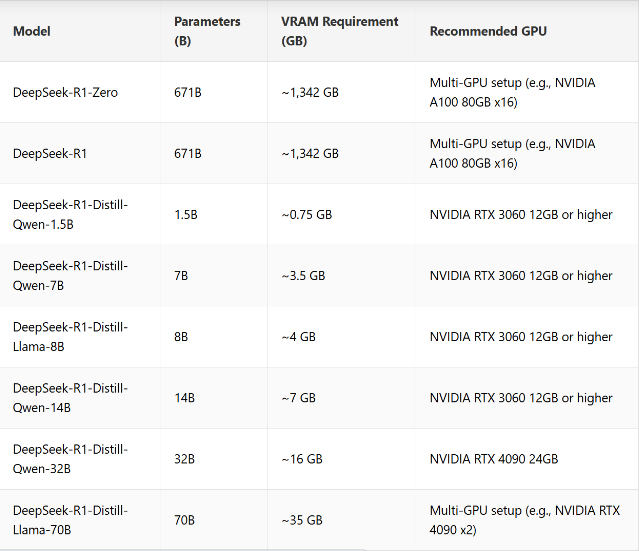
VRAM使用的关键说明:
- 用于较大型号的分布式GPU设置:运行DeepSeek-R1-Zero和DeepSeek-R1需要实质性的VRAM,需要分布式GPU配置(例如,在多GPU设置中NVIDIA A100或H100)才能进行最佳性能。
- 蒸馏模型的单GPU兼容性:蒸馏模型被优化,可在较低的VRAM需求的单个GPU上运行,仅为0.7 GB。
- 额外的内存用法:可能会消耗额外的内存,以进行激活,缓冲区和批处理处理任务。
为什么要在本地运行?
当然,DeepSeek的Web聊天机器人和移动应用程序是免费的,并且非常方便。您无需设置任何东西,并且诸如DeepThink和Web搜索之类的功能都可以在进来。但是,有几个原因为什么在本地运行它可能是一个更好的选择:
- 隐私 :当您使用Web或应用程序版本时,您的查询以及任何文件附件都会发送到DeepSeek的服务器进行处理。该数据会怎样?我们不知道。在本地运行该模型可确保您的数据停留在机器上,从而使您完全控制自己的隐私。
- 离线访问 :在本地运行该模型意味着您不需要Internet连接。如果您旅行,处理斑点Wi-Fi,或者只是更喜欢离线工作,那么本地设置可让您随时随地使用DeepSeek。
- 未来的防护 :DeepSeek的服务现在可能是免费的,但这不太可能永远持续下去。在某个时候,他们需要货币化,并且可能会随后使用限额或订阅费。通过本地运行该模型,您可以完全避开这些限制。
- 灵活性 :使用本地版本,您不仅限于默认设置。想微调模型吗?将其与其他工具集成在一起?构建自定义接口? DeepSeek R-1的开源本质为您带来了无尽的可能性。
在这一点上,尚不清楚DeepSeek如何处理用户数据。如果您不太担心数据隐私,则使用Web或移动应用程序可能是可以使用的方式,因为它们更易于使用并提供DeepThink和Web搜索之类的功能。但是,如果您是关心数据结束的地方,那么在本地运行该模型是一个很好的考虑。
DeepSeek型号的设计旨在即使在不强大的硬件上运行良好。尽管诸如DeepSeek-R1-Zero之类的较大型号需要分布式的GPU设置,但蒸馏版使得可以在单个GPU上顺利运行,并具有较低的要求。如果您不喜欢使用终端,则可以随时使用诸如Gradio或Chatbox AI之类的工具添加简单的UI。